« How This Blog Works »
Posted on 02 August 2018 09:08 in Software
Last updated on 02 August 2018 14:08
meta
history!!
The 2010s web is infinitely harder to participate in than the 90s web. The reason for this has less to do with the tools and more to do with expectations. In 1998 you could get away with having a personal website that looked like this:

This is very little more than H1, IMG, A, B and LI tags, and a couple style properties to float that image and a background image property on the body. Anyone who's touched HTML could make this in their sleep, and in the 90s this was acceptable.
If you wanted to go a little harder, you added a navbar.

That navbar was in a frame. Now, there were issues with frames, but they acknowledged a design intent that many people shared. People want navbars. So when framesets were deprecated (culturally, if not yet technologically) in the 2000s, what did we replace them with? Absolutely goddamn nothing.
Suddenly we wanted to have navbars, but there was no way to do it. Every method was a hack. Should you put the entire website in a table? Not if the sneering nerds have anything to say about it - that's "bad," in some vague undefined way. Should you put in two DIVs with inline-block? Good luck making the second one fill the rest of the screen. Should you put in a float: left DIV for the navbar? Maybe if you hate having free time. I made the quip yesterday that, "In the 2000s we deprecated framesets, creating the job of web designer." I was joking, but only just. You could nearly define "web designer" as "person who implements the Holy Grail Of Web Design."
So navbars aren't the only part of this but I think they illustrate a point. As time went on, sensibilities changed, but certain things have never gone out of style, and have also never been given any proper browser support. Consider this:

Look at the top. See that black bar that runs from left to right? If you're coding a website from scratch you have to know that in order to make that you need to turn off the margin on the BODY tag; microsoft did this in '96 with "leftmargin", "topmargin" etc. in the BODY tag, and the navbar is a table with fixed cell widths. The body itself has a side navbar, incidentally, by using a table layout.
In 1996 this is what corporate websites looked like. Very few individuals had a website like this. But as time went on, things started shifting the window of what was acceptable. This was spurred by the appearance of Frontpage, Dreamweaver and, eventually, make-a-website services (what we know as e.g. Wix now) which offered strictly defined, unmodifiable templates that nonetheless uplifted the average individual with the ability to create websites that looked competent next to those from enterprises. This eventually dead-ended in Medium, which gives any random Joe the same tonal voice of the New York Times, but we won't get into that.
The second thing that happened was the explosion of dynamic websites. In 1998 your personal "journal" page was something you made in Frontpage, maybe, and you made a new journal entry by pressing enter twice at the top of the doc and typing in "<h4>June 12, 1998 - My journey to Alaska</h4>". All you needed was an FTP login to your web host.
By 2006 we expected something far more sophisticated. Look at this blog - it has tag fields which automatically generate index page, categories, created and modified dates that are in metadata fields, there's an index page with blurbs and "read more" links, and there's an archive page that shows posts by date. I've deliberately stripped down the stylesheet, but most of these blogs are far more complex, sometimes even implementing the entire "holy grail." Tumblr, blogger, etc. have navbars with a phenomenal amount of data, often to a fault. It's hard to say no to these things. They make a journal page feel far more like A Website.
So by the mid 2000s, expectations were incredibly high, and the tools... absolutely failed to keep up. In almost all cases these needs were satisfied by CMS', Wordpress leading the pack. Whether Wordpress is as much of a tire fire as I've been led to believe is a matter for debate, but the fundamental question is "Why should data that changes once a day at most be pulled from a database every single time it's viewed by a program with thousands of modules?"
So static website builders came into being. This concept goes way back (Frontpage itself is a static site builder), but in the late 2000s there was an explosion of static site builders created by the open source community. And I hate every single one of them.
static site builders are bad!!
I won't claim I've tried every one of them and the biggest reason for that is that they're almost all Node.js. I think Node is a war crime. I think it sucks and nobody should use it, ever. This is not a topic I want to debate, but I can tell you that a neophyte trying to use it will be absolutely boned in plenty of cases. It is arcane horseshit. So it solves nothing as far as allowing non-webdevs to participate in the web.
As a webdev (not by trade, but i've dabbled for most of my life and built plenty of dynamic and static sites and some apps for work) I understand these Node apps but hate them for unrelated reasons, so I looked for other options a year or so ago and found very little other than Pelican. Pelican's pretty nice! All you do is select a template, then put markdown or HTML files in the 'content' directory and run a command to have it generate an entire site structure for you. Terrific!
The problem is getting content into it. Sure, I can open an HTML file in notepad++ and just type, but like, why? We've had WYSIWYG since the 90s, and everything except Frontpage (debatable) outputs perfectly good code. I can write HTML in my sleep, but I don't fucking want to. That's extra work the computer can do for me, why in hell would I do it myself? Well, The Web seems to disagree, as they usually do, that humans should use ever-improving tools, and instead thinks we should use stone knives and bear skins to build spaceships.
I really dislike markdown. I can't even fully tell you why. Maybe because I have been writing HTML since I was 12 and markdown feels like a step backwards. It's not actually easier, in my eyes, to write markdown - I still have to write opening and closing tags, and I write at 140WPM so whether they're one character or six doesn't matter to me. The problem I actually need solved for web editing is getting images into the doc and versioning. Nothing solves this in a way I'm satisfied with.
Getting images into a hand-written doc means manually uploading the image to the server, manually resizing it on my PC, manually uploading a thumbnail, then manually writing out <a href="/images/thumbs/chrome_example.jpg"><img src="/images/chrome_example.jpg"></a> and that's just too much of a pain in the ass. It's the breaking point for me. I have goddamn ADHD, I'm tired, and I don't have time for that bullshit. So that's why I didn't have a blog until now.
i got fed up!!
I was so sick of this, I was so unbelievably sick of it. I deserve better. I don't want to run a CMS with the potential security issues and massively overwrought featureset, I don't want to manually upload and resize images, and I don't want to have to save my own backups all the time. I hate all that. I hate it to death.
A couple days ago I finally lost my last ounce of patience for this situation and decided to attack the problem. I started by obtaining a copy of Froala, a WYSIWYG HTML editor made in JS. This is not a free tool ($144 - I am going to buy a license shortly), and you could use any WYSIWYG editor honestly - most of what I'm doing is not unique to this editor. Also, JS HTML editors are horrible if you're doing anything sophisticated. The code output is clean but they get easily confused and rarely have reasonable keyboard shortcuts.
I did not want to build an "app." I hate webapps, and this was not an academic pursuit - the purpose of this was to get something done, not accomplish a theoretical technological goal. If I was getting paid I would make an "app" for this, maybe. What I wanted to make was the bare minimum to accomplish my goal, so I implemented everything in plain Python CGI.
I have a create.py that accepts project and doc parameters. From there it reads in project-staging/[project]/content/[doc].html, extracts the metadata fields, then reads in edit.html, which contains a series of text fields for metadata and a textarea that Froala attaches to:
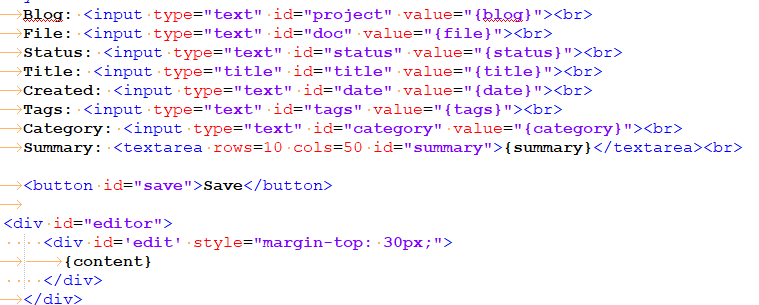

The values for all these fields are replaced by the metadata and body from the selected document. If the document doesn't exist, it uses blanks for these fields so a new doc can be created.
Froala has a save feature, but this could be easily implemented on its own with a simple XHR request, I just used Froala's since it was there. It also supports autosave, which I may implement later. The endpoint for the save feature is write.py, which also accepts project and doc parameters. It makes a backup of the targeted file in /backups, then opens the targeted file, generates a new metadata tag set and body from the POSTed data, and writes it back to the doc. So now I can create and edit files. I've protected this directory, the output is static with no reference to the tools used to create it, and there's no associated database or server process to attack, so this is secure.
Next I had to implement the feature that I chose Froala for: drag and drop image upload. When you drop an image on Froala, it injects the IMG tag into the HTML, then opens an XHR to an arbitrary URL and POST-uploads the image. That endpoint can then reply with a URL where the file can now be reached, and Froala updates the IMG tag SRC attribute to that address. I created image.py to accept these. It stores everything in /uimages using the original filenames, unless there's a conflict, in which case it creates a random filename and returns it.
It also includes a "thumb" attribute in the returned json. I hooked the image.inserted event in Froala and when the uploaded image is injected, I adjust its SRC to the thumb value and then wrap it with an <a> pointing to the uploaded file. I don't actually have a thumb generator right now, but once I do the infrastructure is there to integrate thumbnails.
That's it. All I do at that point is run the update script, which I might be able to hook up to "test deploy" and "publish" buttons in the editor, though I have to figure out how to work my way into a virtualenv from a Python system call was able to create a couple more "draft.py" and "deploy.py" scripts to talk to. There we go, a blog built out of less than 300 lines of Python on top of a prerolled system that does everything I want it to, and I never have to touch a command line.

The only elaboration I might add is a generic file upload feature at some point, but I do that rarely enough I'm comfortable just uploading and linking those by hand.
this sucks so much!!
I shouldn't have had to do this. This was stupid. This was a waste of my time. I am furious that in 2018 the intelligence level of web servers and browsers is still retained at a 1980s level, as if websites are still built around tiny handfuls of resources and huge monolithic HTML docs with very little formatting written in plain text editors. This is not realistic! This does not reflect the improvements in technology and expectations of the last 30 years, and I think it's pathetic that only people who can do something like I did get to have a reasonable time creating and maintaining websites.
All the functionality I implemented should have been things my web browser could do with authenticated, SSL-encrypted GET, POST and PUT statements. That's how hypertext was supposed to work, and the technology exists, but nobody will admit that the web isn't what it was in 1995 and we need better god damn tools. Node and web-based editors are not the solution, they're just a half-ass, hacked-together mess that works within a structure we created and perpetuate and that refuses to actually challenge a status quo that actively makes life worse for everyone.
As a case in point: Froala's italics behavior is completely random. I can type in text in italics, then Ctrl+I and watch the toolbar italic icon turn off, then when I type again italics are back. In the implementation I'm using on a project at work this has never happened once. So I've taken to the practice of continuing to type after I'm done with the italics, then selecting back to the last word I typed and un-italicing, and that works pretty well, except on the last paragraph it just stopped working. No amount of ctrl+I or erasing and retyping would help. I had to go to HTML view and manually move the <i> to the right position.
This is pathetic, and unnecessary. There are WYSIWYG editors that have been in development for years and still have these problems, but Microsoft Expressions Web 4 is a native Windows app and it has these errors exactly never. Dreamweaver didn't have these errors. Frontpage barely had them. But none of these solve this problem either because they aren't designed around an intent of feeding a static site generator. I tried using Expressions and it's just not targeted for making a dynamic-esque website like this.
I have had fantasies about fixing this myself. With some minor elaborations on the script i've made so far, I could make this far more robust and automated and user-friendly, and then package a tiny webserver, Python, bundle of scripts, etc. in a portable package that anyone could install, like Node but not a slow, complicated, memory-hogging heap of shit. And then I ask myself why it would be reasonable for one spiteful dick to fix a problem that thousands of Industry Influencers conspired to create through inaction and cowardice, and I go work on other projects, because down that road Github lies.
View/Add comments (Warning: provided by Disqus and may include ads! Hidden for your safety!)